This year has started with a lot of deep thoughts about the software 2.0. My conclusion (which is slightly different from Andrej Karpathy’s consideration) is that a software 2.0 is a combination of a Neural network model and its associated weights. This is a concept; now the question is: how to materialize the idea? What artifact represents a software 2.0.
I emitted several ideas and tried one of them: to serialize the mathematical model and the weights. The main drawback of this idea is that it is not easy to write down and to parse any mathematical equation. The best way to express a model is, as of today, via its computation graph (this is what most ML frameworks are doing).
Therefore, switching from a mathematical representation to the computation graph representation might lead to an excellent way to express the artifact of a software 2.0.
A quick word about ONNX
Describing a computation graph is straightforward. A computation graph is a Directed Acyclic Graph (DAG). Each node of the graph represents a tensor or an operator. The challenge is to find a domain specific language (DSL) to describe a graph in a way that it is agnostic of its implementation.
This is the promise of ONNX. ONNX stands for Open Neural Network eXchange (format). The purpose of this project is to establish an open standard for exporting/importing ML models.
In this post, I will describe the first step I have made to be able to read (and hopefully) execute an ML model encoded via ONNX into the Go ecosystem.
I am, for now, only working to import a model from ONNX into Go. Export may come further.
From the protobuf definition to a Go structure
ONNX is a description of a model made in protocol buffers (protobuf). In this section, I will dig a little bit into the protobuf definition file of ONNX. Then let’s create a first Go code to read and import a model.
What are protocol buffers?
The most accurate definition comes obviously from the official website:
Protocol buffers are Google’s language-neutral, platform-neutral, extensible mechanism for serializing structured data – think XML, but smaller, faster, and simpler. You define how you want your data to be structured once, then you can use special generated source code to easily write and read your structured data to and from a variety of data streams and using a variety of languages.
It is a way to serialize messages. For short, a protobuf file describes an API contract. The contract is expressed via the protobuf DSL. Then we use a compiler to transpile this API into a native language API (for example, you can turn the definition into a set of Java classes, or Go structures). Once a message is serialized, it is represented in a binary format.
Note: I will not go deeper in the protobuf description here. But, in my humble opinion, it is a perfect way to express an API when implementing a machine-to-machine communication. Better than JSON because of its simplicity, efficiency and the ability to validate a schema natively.
But let’s go back to ONNX. The primary definition file for ONNX (the API contract) is hosted here and is named onnx.proto3.
This is the file used to generate bindings to other languages.
To create a bridge between the protobuf binary format and the Go ecosystem, the first thing to do is to generate the Go API. This will allow to read an ONNX file and to transpile it into a Go compatible object.
To do this, I am using the protoc compiler. I am also using the alternative compiler gogoprotobuf which add some useful features (such as fast Marshaller/Unmarshaler methods). For clarity, I will not describe how to install and use the protoc binary.
Merely running protoc --gofast_out=. onnx.proto3 will generate a file onnx.pb.go which is usable out-of-the box.
onnx-go
After some discussions with the official team, we agreed that, before the onnx-go package reaches a certain level maturity, it was best to host it on my personal GitHub account. So, as of today, I am hosting the repository here: github.com/owulveryck/onnx-go. The corresponding Godoc is hosted here.
This package on its own is enough to read an ONNX format.
Testing the package
As I said before, I want to work on the import. So let’s get a properly encoded ONNX file to test the generated package. The ONNX organization has set up a model repository (model zoo). From this repository, let’s extract the basic MNIST example to get a real life ONNX model.
curl https://www.cntk.ai/OnnxModels/mnist/opset_7/mnist.tar.gz | \
tar -C /tmp -xzvf -
Now, let’s write a simple program that will read the ONNX file and decode it into an object of type ModelProto (which is the top-level object in the ONNX file).
Then create a very simple Go program to read and dump the model:
| |
Note: I am using the q package to dump the content as the output is verbose. The result is present in the file $TMPDIR/q
From the Go structure to a Graph
Now that we are able to read and decode a binary file let’s dig into the functional explanation.
Graphs
The ONNX Model document is made of several structures. One of those structures is the GraphProto. From the documentation we read that:
A graph defines the computational logic of a model and is comprised of a parameterized list of nodes that form a directed acyclic graph based on their inputs and outputs. This is the equivalent of the “network” or “graph” in many deep learning frameworks.
As a consequence, the vertices of the graph are composed of nodes that may be Operators or Tensors. The Tensors can be a computable (learnable) element (defined by the type TensorProto) or values (defined in the type ValueInfoProto). Values are actually not computable. This means that a value is not learnable; most likely it is the input of the neural net.
As a consequence, the primary types mandatory to reconstruct the computation graph are:
In ONNX, all those elements are identified by their name which is a string.
The GraphProto structure is made of:
- a list of inputs of type
ValueInfoProto - a list outputs of type
ValueInfoProto - a list of “Initializers” used to specify constant inputs of the graph of type
TensorProto - a list of operations of type
NodeProto
Despite the naming of the different types, they will all be converted to node (in the sense of vertices) of the graph I am creating.
Nodes
In ONNX, a node is a special type that holds an operator. In this section, a node will represent a NodeProto and I will use the term vertex to describe its implementation in the graph.
Again from the documentation, we read that:
Computation graphs are made up of a DAG of nodes, which represent what is commonly called a “layer” or “pipeline stage” in machine learning frameworks.
Note: This documentation is present “as-is” in the GoDoc and has been auto-generated from the (protobuf) definition; it’s one of the reasons why I said the protobuf is more flexible than JSON for writing API contracts.
A node knows its inputs and its output. Therefore, to generate the graph, we should:
- start by adding the inputs (which are particular vertices with an indegree of 0). For commodity, we will track the added node into a “dictionary” of vertices (a Go map).
- add every single node reachable only from vertices presents in the dictionary.
- add the edges
- add the current vertex to the dictionary.
Note: In ONNX, the NodeProto has a type and a name. The name is used as input for its successors. The type is representing the actual mathematical operator that will be applied to the inputs; we will see that later.
Gonum
To test and evaluate the structure in the Go environment, let’s create a simple graph with the help of the Gonum’s Graph package. I will keep it simple and use the “simple” implementation.
First, let’s define a wrapper struct:
| |
where db is the dictionary of nodes (vertices) as described in the previous section.
Node
Let’s then define a simple node (vertex) structure that will fulfill the Node interface.
The structure will handle various information later, but for now, let’s start with its name and the operation type:
| |
Building the DAG
Let’s define a wrapper struct. This will give us the flexibility to add (at least) a method to parse the graph later; this will ease the work when we switch to Gorgonia for computing the graph.
| |
To parse the graph we will process the Initializers, the Inputs and the Nodes (let’s forget the outputs for now).
| |
Now a bit more tricky, let’s add the Operators and the edges of the graph.
The nodes (NodeProto) are supposed to be in topological order in the ONNX model,
but let’s ignore this information and reconstruct the graph as explained before (by reconstructing the topology from the inputs/initializers to the output).
The algo I am using consists in removing items from the node list once it is processed and waiting for the list to be empty. There is a condition that exit the loop, just in case the graph is not a valid DAG.
Note: maybe a recursive algorithm would be more efficient, but efficiency is not an issue here.
For clarity, I will not copy the whole code here. Please visit the GitHub repo for more information.
The critical point is that for each processable node we call a method of the computationGraph structure call processNode. This method evaluates the content of the node (its inputs and its name), add it to the graph and place the edges the node has with its ancestors (inputs).
Displaying the result
Thanks to the dot encoding capability of the graph package of Gonum, it is easy to generate an output that is compatible with Graphviz.
By taking back and completing the MNIST example, gluing a little bit and adding particular methods for the node object (DOTID,…), we obtain this output:
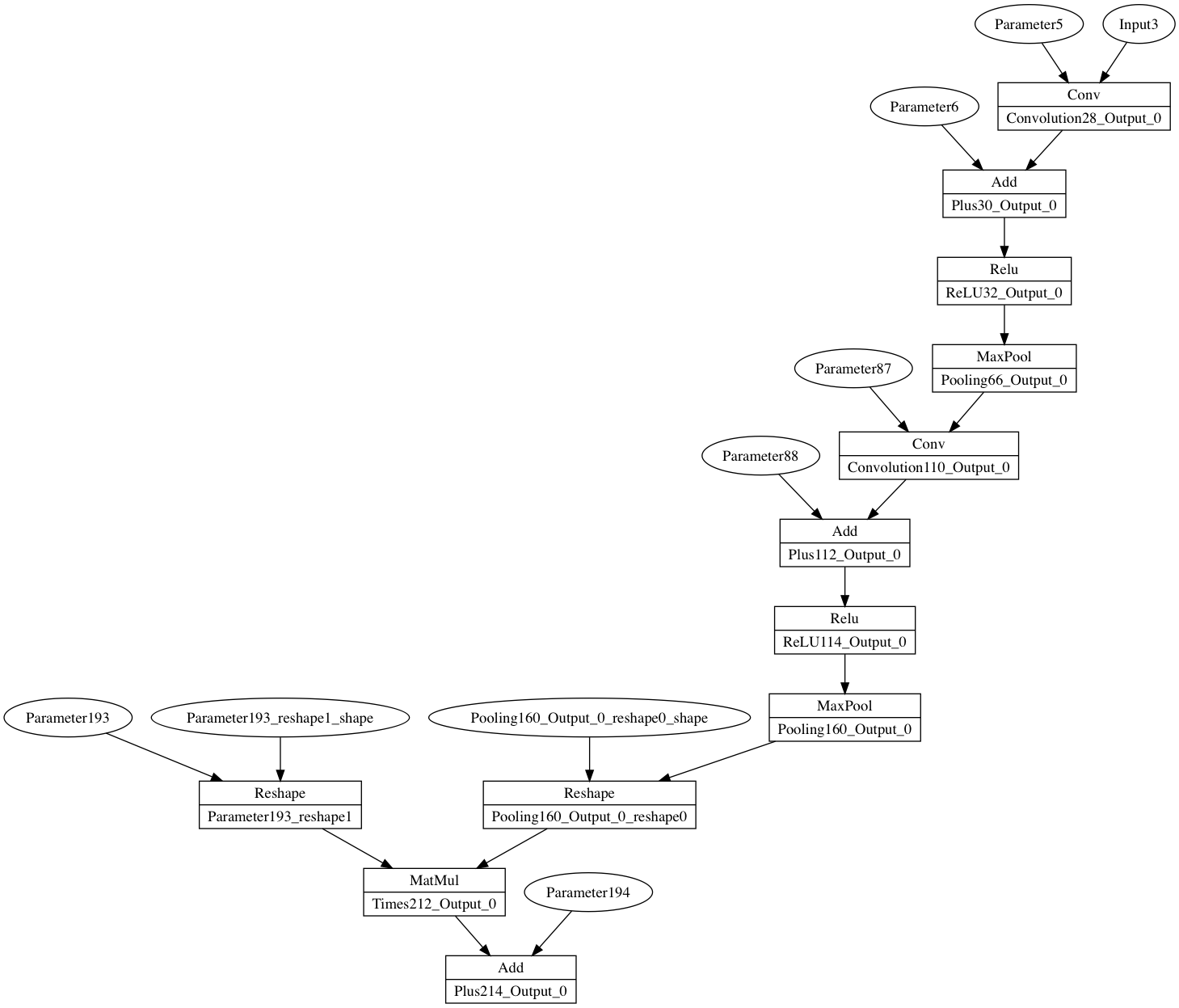
{kind=link}
The graph looks good and is actually representing a convolution neural network. This is the end of the first part.
In the next article, let’s implement a real backend to be able to compute and evaluate the graph.
Conclusion
We are now able to read and understand the information encoded into an ONNX model. The next step is to be able to create a real computation graph that can process the input to produce a result. That is what we will do in a second post.
So far, with Go, we can write small utilities to extract various pieces of information and represent the models. This is independent of any framework and can be used as a standalone tool.