About TOSCA
The TOSCA acronym stands for Topology and Orchestration Specification for Cloud Applications. It’s an OASIS standard.
The purpose of the TOSCA project is to represent an application by its topology and formalize it using the TOSCA grammar.
The [TOSCA-Simple-Profile-YAML-v1.0] current specification in YAML introduces the following concepts.
- TOSCA YAML service template: A YAML document artifact containing a (TOSCA) service template that represents a Cloud application.
- TOSCA processor: An engine or tool that is capable of parsing and interpreting a TOSCA YAML service template for a particular purpose. For example, the purpose could be validation, translation or visual rendering.
- TOSCA orchestrator (also called orchestration engine): A TOSCA processor that interprets a TOSCA YAML service template then instantiates and deploys the described application in a Cloud.
- TOSCA generator: A tool that generates a TOSCA YAML service template. An example of generator is a modeling tool capable of generating or editing a TOSCA YAML service template (often such a tool would also be a TOSCA processor).
- TOSCA archive (or TOSCA Cloud Service Archive, or “CSAR”): a package artifact that contains a TOSCA YAML service template and other artifacts usable by a TOSCA orchestrator to deploy an application.
My work with TOSCA
I do believe that TOSCA may be a very good leverage to port a “legacy application” (aka born in the datacenter application) into a cloud ready application without rewriting it completely to be cloud compliant. To be clear, It may act on the hosting and execution plan of the application, and not on the application itself.
A single wordpress installation in a TOSCA way as written here is represented like that
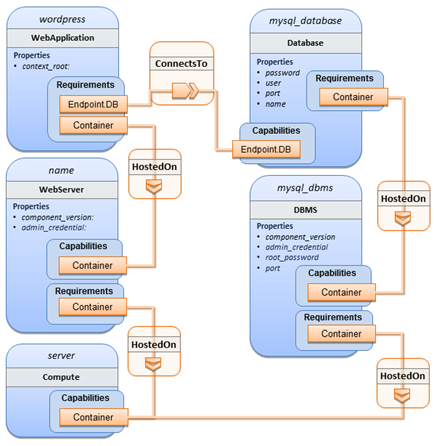
While I was learnig GO, I have developped a TOSCA lib and a TOSCA processor which are, by far, not idiomatic GO.
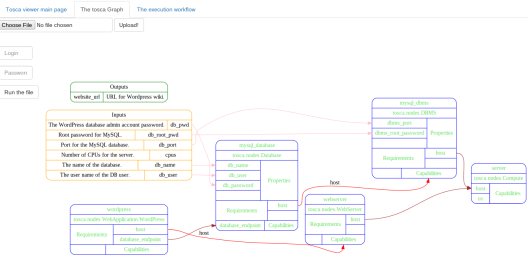
Here are two screenshots of the rendering in a web page made with my tool (and the graphviz product):
The graph representation of a Single instance wordpress
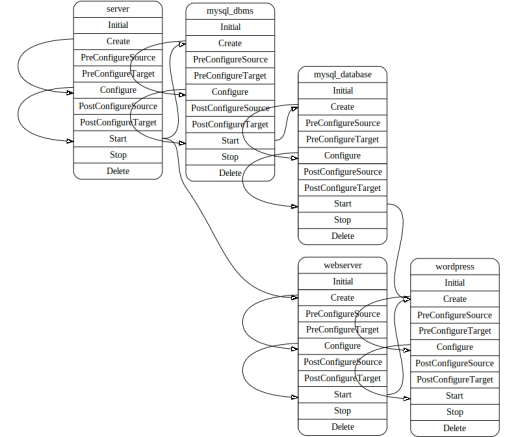
The graph representation of a lifecycle of Single instance wordpress
The TOSCA file is parsed with the help of the TOSCALIB and then it fills an adjacency matrix (see FillAdjacencyMatrix)
The graphviz take care of the (di)graph representation.
What I would like to do now, is a little bit more: I would like to play with the graph and query it Then I should perform requests on this graph. For example I could ask:
- What are the steps to go from the state Initial of the application, to the state running ?
- What are the steps to go from stop to delete
- …
and that would be the premise of a TOSCA orchestrator.
The digraph go code
I’ve recently discoverd the digraph tool, that I will use for querying the graphs.
The digraph is represented as a map with a node as a key and its immediates successors as values:
| |
From TOSCA to digraph
What I must do is to parse the adjacency matrix, get the “lifecycle action” related to the id and fill the graph g.
Let’s go
Considering the digraph code, what I need to do is simply to override the parse method.
Principle
I will fill the graph with a string composed of nodename:action as key.
For example, if I need to do a “Configure” action of node “A” after a “Start” action on node “B”, I will have the following entry in the map:
| |
So What I need to do is to parse the adjjacency matrix, do a matching with the row id and the “node:action” name, and fill the graph g with the matching of the corresponding “node:action”.
I will fill a map with the id of the node:action as key and the corresponding label as values:
| |
Then I can easily fill the graph g from the adjacency matrix:
| |
That’s it
The final function
Here is the final parse function
| |
Grab the source and compile it
I have a github repo with the source. It is go-gettable
go get github.com/owulveryck/digraph
cd $GOPATH/src/github.com/owulveryck/digraph && go build
EDIT As I continue to work on this tool, I have created a “blog” branch in the github which holds the version related to this post
Example
I will use the the same example as described below: the single instance wordpress.
I’ve extracted the YAML and placed in in the file tosca_single_instance_wordpress.yaml.
Let’s query the nodes first:
| |
so far, so good…
Now, I can I go from a Server:Create to a running instance wordpress:Start
curl -s https://raw.githubusercontent.com/owulveryck/toscaviewer/master/examples/tosca_single_instance_wordpress.yaml | ./digraph somepath server:Create wordpress:Start
server:Create
server:Configure
server:Start
mysql_dbms:Create
mysql_dbms:Configure
mysql_dbms:Start
mysql_database:Create
mysql_database:Configure
mysql_database:Start
wordpress:Create
wordpress:Configure
wordpress:Start
Cool!
Conclusion
The tool sounds ok. What I may add:
- a command to display the full lifecycle (finding the entry and the exit points in the matrix and call somepath with it)
- get the tosca
artifactsand display them instead of the label to generate a deployment plan - execute the command in
goroutinesto make them concurrent
And of course validate any other TOSCA definition to go through a bug hunting party